
The Evolving Face of GUI (III) – Computer-Use Agents
Preface: Are Grounding Tasks All They’re Grounded to Be?
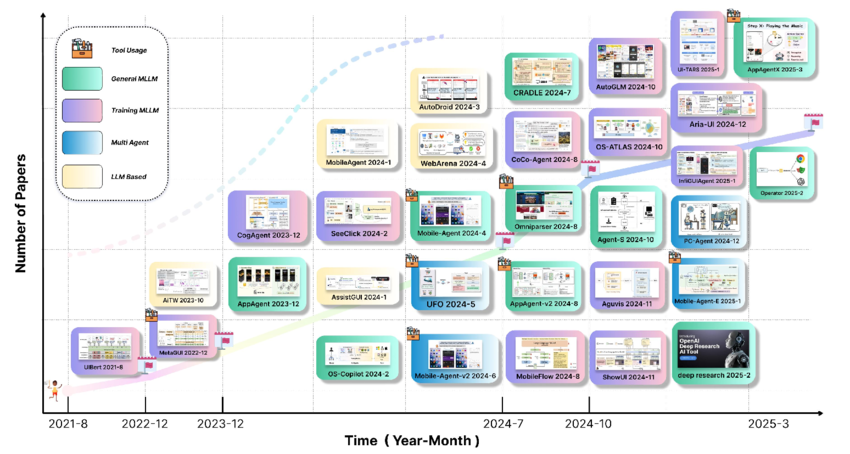
Research on GUI agents has advanced rapidly since the release of early grounding datasets such as the ScreenSpot series, with these benchmarks reaching saturation within a remarkably short time. However, despite the rapid advancement of GUI grounding techniques, current approaches often fail to capture the inherent complexity of real-world GUI interactions, reducing them to oversimplified element grounding tasks. This limitation has prompted a fundamental shift in focus—from grounding individual elements to developing end-to-end agents capable of performing complete GUI-based tasks. In practical scenarios, comprehensive computer-use tasks demand a multifaceted approach that extends far beyond simple grounding, encompassing long-horizon planning, sophisticated action space modeling, and multi-step reasoning. To address these complex requirements, robust systems may incorporate memory modules for context retention across interactions and leverage API integration to enhance operational efficiency, marking an evolution from isolated grounding capabilities to holistic task execution frameworks.
1. Datasets and Benchmarks
In order to train and evaluate robust computer-use agents, the community has built both open trajectory datasets (for agent training / imitation) and benchmarks / evaluation suites (for measuring task success, generalization, and robustness). Below are expanded lists of each, incorporating the newest works as of 2023–2025.
Open-source Datasets
Over recent years, several groups have released open datasets of GUI interaction traces (screenshots, states, actions, reasoning traces) across desktop, mobile, and hybrid interfaces. These datasets serve as the raw substrate for training and pretraining agents—from imitation to reinforcement learning.
- OS-Genesis — A pioneering data construction pipeline for generating large-scale, high-quality GUI interaction trajectories. By combining agent synthesis, human correction, and iterative refinement, OS-Genesis enables scalable data generation across multiple operating systems, significantly reducing the manual annotation burden while maintaining trajectory quality.
- AgentNet (OpenCUA) — The flagship desktop trajectory dataset in the OpenCUA project. It contains 22.5K human-annotated computer-use tasks across Windows, macOS, and Ubuntu (12K from Windows, 5K macOS, 5K Ubuntu), spanning 140+ applications and 190 websites. Each trace includes state, action, and chain-of-thought reasoning per step.
- Computer-Browser-Phone-Use Agent Datasets (Khang-9966 repo) — A community-curated catalog of datasets used for GUI agents, covering web, mobile, and desktop interactions (click/typing/navigation) with screenshots, element maps, and action logs.
- GUI-World — A multimodal GUI-oriented video dataset containing over 12,000 annotated video clips across desktop, mobile, XR contexts. It includes temporally grounded annotations (keyframes, operation history) to assess dynamic GUI understanding.
- ScaleCUA (2025) — A newly proposed dataset scaling open-source GUI agent training; it spans 6 operating systems and 3 task domains using a closed-loop pipeline of agent synthesis + human correction. It reports strong gains over baselines (e.g. +26.6 on WebArena-Lite, +10.7 on ScreenSpot-Pro) and sets new state-of-the-art open benchmarks.
- macOSWorld — Designed specifically for the macOS domain with 202 multilingual interactive tasks across 30 apps (28 of which are macOS-exclusive). It also includes a safety/deception-testing subset and multilingual instructions in 5 languages.
These datasets help agents learn cross-platform behaviors and multimodal reasoning. The inclusion of multiple OS types, diversity of applications, and chain-of-thought annotations are key trends pushing toward generalist agents. OS-Genesis represents a significant step toward automating dataset creation at scale.
Core Benchmarks for Computer-Use Agents
Benchmarks provide standard tasks and metrics to compare agent capabilities. They are broadly categorized into online benchmarks, which evaluate agents in live, interactive environments, and offline benchmarks, which test an agent’s ability to predict actions or understand states based on static, pre-recorded datasets.
| Benchmark | Type | Description |
|---|---|---|
| MMBench-GUI | Online | A hierarchical, multi-platform framework (6 OSes) that assesses agents from basic GUI understanding to complex multi-app tasks, introducing the EQA metric to measure both success and efficiency. |
| OSWorld | Online | A unified benchmark for evaluating multimodal agents on open-ended tasks in real computer environments, including Ubuntu, Windows, and macOS. |
| Windows Agent Arena | Online | A benchmark for evaluating multi-modal OS agents at scale within the native Windows OS, featuring a diverse set of real-world desktop tasks. |
| AndroidWorld | Online | A dynamic benchmarking environment for training and evaluating autonomous agents on the Android platform, requiring them to complete tasks across various apps. |
| VisualWebArena | Online | A vision-centric version of the WebArena benchmark that blocks access to underlying HTML, forcing agents to operate based solely on visual information. |
| GUI-Odyssey | Offline | A comprehensive dataset and benchmark for evaluating cross-app GUI navigation on mobile devices based on expert demonstrations. |
| Android-in-the-Wild | Offline | A large-scale, offline dataset of unscripted, real-world human interactions with Android devices, capturing the complexity of everyday usage. |
| Mind2Web | Offline | An offline benchmark for web agents, designed to evaluate a generalist agent’s ability to follow natural language instructions on a wide range of real-world websites. |
Together, this suite of online and offline benchmarks provides a robust framework for assessing agent capabilities. Offline benchmarks are crucial for evaluating action prediction and representation learning on large-scale data, while online benchmarks test an agent’s true ability to plan, act, and recover from errors in dynamic environments.
2. E2E Training
With the advent of multimodal large language models (MLLMs) and agentic reasoning frameworks like ReAct, many works now exploit an LLM’s visual perception and planning capabilities to build computer-use agents. Early pioneers include OpenAI’s Operator and Anthropic’s Computer-Use Agent. In open-source terrain, UI-TARS and others have led the push for fully transparent agent models.
Below is an overview of representative E2E agent systems and model families (2023–2025), along with their training strategies and architectural contributions.
| Model / System | Highlights & Approach | Key Strengths / Tradeoffs | Training Paradigm |
|---|---|---|---|
| OS-Atlas | A foundational GUI action model trained via SFT on the largest open cross-platform GUI grounding dataset (13M+ elements), emphasizing generalization. | Powerful open-source baseline excelling at GUI localization and zero-shot generalization to unseen interfaces. | SFT |
| PC Agent-E | Uses only 312 human trajectories + Trajectory Boost (LLM-assisted augmentation) to train an efficient agent that outperforms stronger baselines. | Highly data-efficient; proves that small, high-quality datasets with augmentation can yield strong agents. | SFT (Behavior Cloning) |
| ShowUI | Proposes a unified Vision-Language-Action (VLA) model that handles perception, understanding, and action generation end-to-end, focusing on mobile GUI tasks. | Simplified architecture with strong alignment between components; potentially limited on complex desktop tasks requiring deep reasoning. | SFT |
| Aguvis | A unified, pure-vision agent framework that uses a two-stage training process (vision-language pre-training + instruction SFT) for diverse GUI tasks. | Generalizes well by relying only on pixels, not metadata; may be challenged by tasks requiring fine-grained text parsing from the UI. | Pre-training + SFT |
| GUI-Owl (Mobile-Agent-v3) | A foundational model (GUI-Owl) is enhanced by the Mobile-Agent-v3 framework, which iteratively self-evolves its data via simulated exploration and RL-based refinement. | Exemplifies true cross-platform generalism; continuously improves through a self-refinement loop. | Trajectory-aware Relative Policy Optimization for Online Environment RL |
| ScaleCUA | Focuses on scaling data: trains via SFT on a massive dataset spanning six OSes and multiple domains to improve agent robustness. | Emphasizes scale and data coverage, facilitating improved agent robustness and generalization. | SFT |
| UI-S1 | Introduces a semi-online reinforcement learning framework to bridge the gap between offline pre-training and online fine-tuning, improving RL efficiency. | Significantly improves sample efficiency and stability of RL training; requires a well-curated offline dataset to initialize the policy. | Semi-Online RL |
| UI-TARS | A pioneering open-source GUI agent designed with unified modeling across OS types, using multimodal reasoning and action planning. | Community-leading open agent architecture that acts as a reusable baseline for research. | CPT + SFT/DPO |
| UI-TARS-2 | The successor to UI-TARS, introducing end-to-end reinforcement learning for improved autonomous GUI interaction. | Advances the UI-TARS framework with RL-based policy optimization for better task completion. | End-to-End RL |
Training techniques & trends:
- Many recent works adopt a pipeline of supervised fine-tuning (SFT) → preference tuning / DPO → RL or self-improvement, blending imitation and reward-based learning.
- Trajectory augmentation (as in PC Agent-E) is increasingly popular: using LLMs to expand or diversify human trajectories before training.
- Joint training for grounding + reasoning modules (rather than separate isolated modules) is gaining traction.
- Self-improving loops (agent executes, reviews, refines its own data) are a rising paradigm (Mobile-Agent-v3 uses this).
- Models often treat the screen + mouse/keyboard interface as universal, making the same core agent usable on both mobile and desktop.
3. Multi-Agent Architectures
Relying on a single monolithic model for all GUI capabilities can limit specialization and adaptability as tasks vary wildly (e.g. form-filling vs. file management vs. app-specific flows). To address this, several recent works decompose agents into collaborating submodules or specialists.
- Agent S2 exemplifies this: it uses a generalist planner plus specialist grounding / reasoning modules, with a custom Mixture-of-Grounding that dispatches to the best specialist per UI context.
- UFO / Desktop AgentOS (Microsoft) employs a HostAgent + AppAgents architecture: HostAgent decomposes tasks, and AppAgents (per app) handle execution via vision + native UI Automation. This hybrid approach improves reliability and error recovery.
- Module-based pipelines in UI agent projects: many models internally split perception, grounding, plan generation, and action modules — though not always as independent agents, the conceptual modularization helps debugging, scaling, and flexibility.
Modular and multi-agent designs improve flexibility and robustness. For instance, if a grounding module fails, a fallback specialist can intervene; or a planning module can be replaced or updated without retraining perception.
4. Hybrid Architectures: Combining End-to-End RL with Multi-Agent Systems
Though multi-agent frameworks harness context engineering, role separation, and task decomposition, their cascaded or pipelined structure can subtly accumulate errors and constrict the performance ceiling of the underlying model. In those designs, mistakes in grounding or planning propagate downstream agents, amplifying deviations. This limitation has motivated hybrid architectures that combine an end-to-end, GUI-trained foundational model with multi-agent orchestration for optimization, error correction, and task decomposition.
One prominent example is Mobile-Agent-v3, which uses GUI-Owl as its foundational backbone and wraps a multi-agent system (MAS) around it for enhanced control and robustness. GUI-Owl is trained as an end-to-end multimodal agent (vision → grounding → planning → action), capable of operating directly on desktop and mobile interfaces. Then Mobile-Agent-v3 orchestrates specialized agents (e.g. Manager, Worker, Reflector, Notetaker) to supervise, reflect, and guide the execution of long-horizon tasks using dynamic replanning, memory, and error recovery. This hybrid approach mitigates cascading error drift while retaining the capacity and flexibility of a single, learned core model.
5. Cross-Platform Approaches
Achieving universality — i.e. one agent that works well across desktop, mobile, and web — is a key ambition. Hybrid strategies help bridge domain gaps and make cross-platform generalization possible.
- Unified interface abstraction: Many agents (CUA, PC Agent-E, UI-TARS) treat the GUI as a rendering + mouse/keyboard action space, hiding OS-specific APIs under a universal interface. This allows the same core agent to act on both Android, Windows, macOS, and web.
- Hybrid control (vision + native APIs): For example, Microsoft’s UFO leverages native UI Automation where possible and falls back to vision-based control otherwise. This increases robustness and reduces brittleness.
- Cross-OS trajectory synthesis / self-evolution: Mobile-Agent-v3’s training pipeline runs agents in Android, Ubuntu, Windows, macOS environments in cloud infrastructure, generating trajectories that span OS types.
- ScaleCUA’s cross-platform dataset: By training agents on diverse operating systems (six OSes) and domains, ScaleCUA encourages models that generalize across devices.
- macOSWorld: macOSWorld fills a gap by explicitly focusing on macOS GUI tasks (including multilingual and safety scenarios), helping to adapt agents to that domain.
By combining shared modeling, API fallback, cross-platform data, and modular interfaces, hybrid architectures approach the goal of a general GUI agent.
6. Challenges in Current Research
Even with all these advances, computer-use agent research faces several persistent and emerging challenges. Below I elaborate each with concrete examples and recent mitigation techniques.
Generalization to Unseen Interfaces and Apps
Agents often overfit to UI layouts or app families seen in training. When presented with new designs, rare applications, or multilingual interfaces, they fail to adapt. For example, current models struggle with specialized domain applications such as hardware control utilities (e.g., Lenovo Legion Zone), vendor-specific OEM software, or niche productivity tools that rarely appear in training corpora.
- Mitigation: Employ diverse cross-platform datasets (ScaleCUA, AgentNet, GUI-World) and multilingual benchmarks (macOSWorld’s 5-language support) to broaden exposure. Data augmentation techniques such as LLM-based trajectory blending (e.g., PC Agent-E’s Trajectory Boost) help synthesize diverse interaction patterns. Training on long-tail app coverage and domain-specific UI patterns (including OEM software and niche utilities) improves robustness. Additionally, designing specialized pre-training tasks focused on UI element recognition, layout understanding, and cross-domain transfer can enhance the model’s foundational visual comprehension.
- Open problem: true zero-shot adaptation to wholly new domain types (e.g., VR apps, games, OEM utilities, novel UI style languages) and low-resource language interfaces remains largely unsolved.
Long-Horizon Planning & Sparse Rewards
Complex tasks (e.g. “organize files, then email results”) require tens of steps and delayed feedback.
- Mitigation: Hierarchical planning, semi-online RL (UI-S1 style), reward shaping, Curriculum Learning.
- Open problem: maintaining robustness and recovery in long sequences with branching branches.
Safety, Robustness & Error Recovery
Agents interacting with GUI risk performing unsafe or destructive actions (e.g. closing important documents, clicking malicious popups) and prompt injection from Pop-ups.
- Mitigation: Action masking, human-in-the-loop confirmation, state rollback / undo modules, safety benchmarks (macOSWorld includes deception tests).
- Open problem: guaranteeing safety in open environments with adversarial UIs or unseen popups.
Efficiency, Memory & On-Device Inference
Running giant models is expensive, particularly on mobile or desktop inferences, and inference time for each step might be intolerable.
- Mitigation: Quantization, smaller models (AgentCPM, 8B), vector memory modules (e.g. UFO’s memory), caching embeddings, state compression.
- Open problem: balancing model capacity vs latency vs reliability in real-world GUI tasks.
Proactivity and Autonomy
Most agents are reactive: they wait for instructions and then act. Proactive agent behaviors (anticipating user needs, automating routine flows) is barely explored.
- Mitigation: Some modular frameworks (AgentKit, Agent S2) allow agent chaining or planning ahead; feedback loops and user profiling modules may help.
- Open problem: trust, interpretability, autonomy governance — how to let the agent act without unwanted surprises.
References
[1] OpenCUA: Open Foundations for Computer-Use Agents
[2] Computer-Browser-Phone-Use Agent Datasets (Khang-9966)
[3] GUI-World: A Dataset for GUI-Oriented Multimodal LLM-based Agents
[4] ScaleCUA: Scaling Open-Source Computer Use Agents with Cross-Platform Data
[5] macOSWorld: A Multilingual Interactive Benchmark for GUI Agents
[6] OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks
[7] Efficient Agent Training for Computer Use (PC Agent-E)
[8] ScreenSuite - The most comprehensive evaluation suite for GUI agents
[9] OSUniverse: Benchmark for Multimodal GUI-navigation AI Agents
[10] Operator - OpenAI’s Computer-Using Agent
[11] Agent S2: A Compositional Generalist-Specialist Framework for Computer Use Agents
[12] Mobile-Agent-v3: Foundamental Agents for GUI Automation
[13] GUI agents resource lists (trycua/acu)
[14] OS-Atlas: A Foundation Action Model for Generalist GUI Agents
[15] Anthropic’s Computer Use Agent (Claude 3.5 Sonnet)
[16] ShowUI: One Vision-Language-Action Model for GUI Visual Agent
[17] Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction
[18] UI-S1: Semi-Online Reinforcement Learning for GUI Agents
[19] UI-TARS: Pioneering Automated GUI Interaction with Native Agents
[20] UI-TARS2: Reinforcement Learning for GUI Agents
[21] OS-Genesis: Automating Data Curation for Vision-Language-Action Models
[22] MMBench-GUI: A Hierarchical Multi-Platform GUI Benchmark
[23] Windows Agent Arena: Evaluating Multi-Modal OS Agents at Scale
[24] AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
[25] VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
[26] GUI-Odyssey: A Comprehensive Dataset for Cross-App GUI Navigation
[27] Android in the Wild: A Large-Scale Dataset for Android Device Control
[28] Mind2Web: Towards a Generalist Agent for the Web